Transfer-learning through Fine-tuning: What Parameters to Freeze?
This project was done as a Semester Project at EPFL’s Machine Learning and Optimization Laboratory. The goal was to investigate the effect of freezing parameters in a pre-trained BERT model. We used the GLUE benchmark to evaluate the performance of our models.
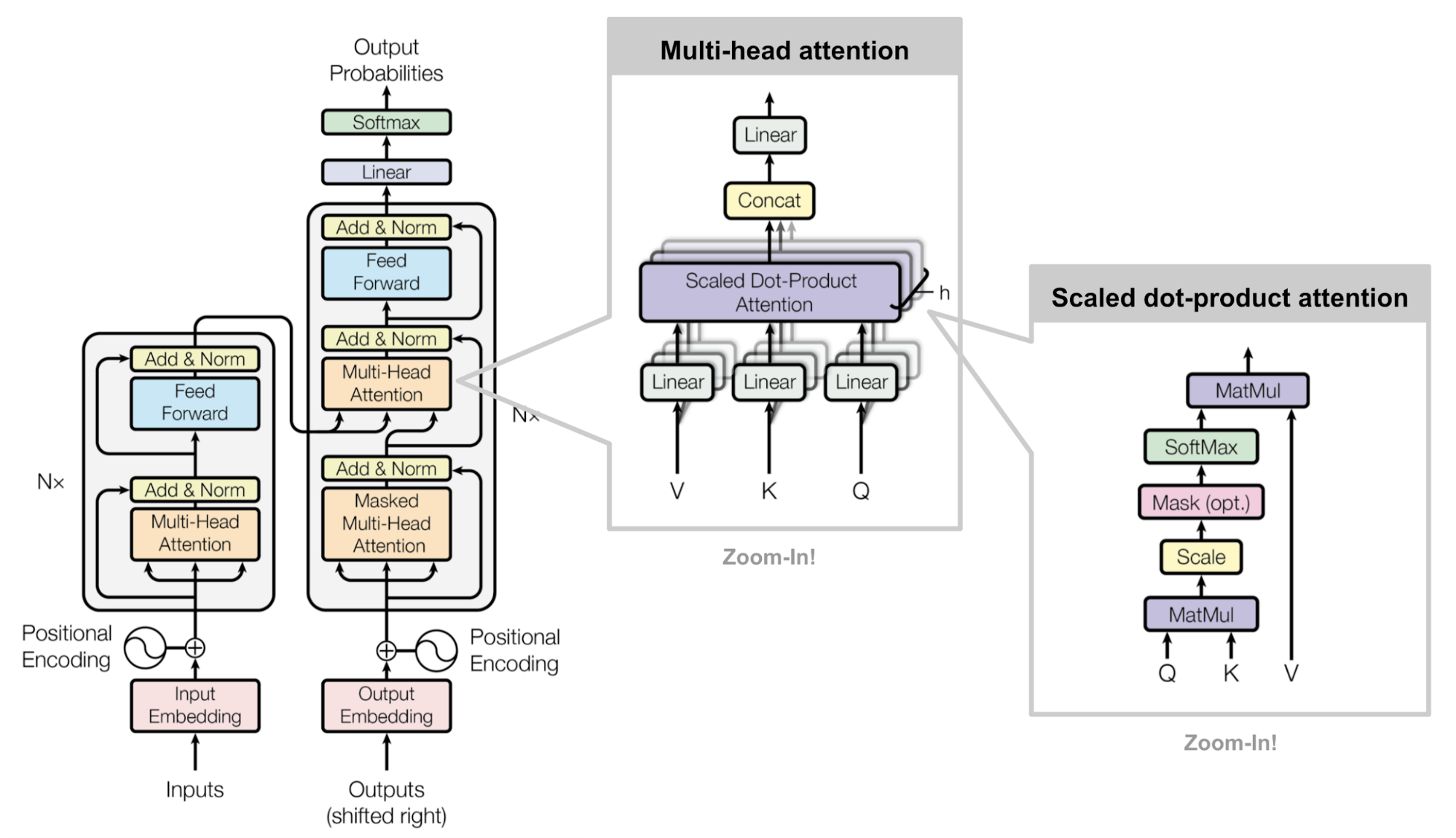
In the context of finetuning, freezing a given set of parameters is of interest, as it allows to reduce the number of parameters to train, and thus the training time. Note also that, to solve different tasks, the same backbone model can be trained on different datasets. In this case, freezing parameters means that not all parameters need to be saved and loaded for each task, but only the parameters that were not frozen.
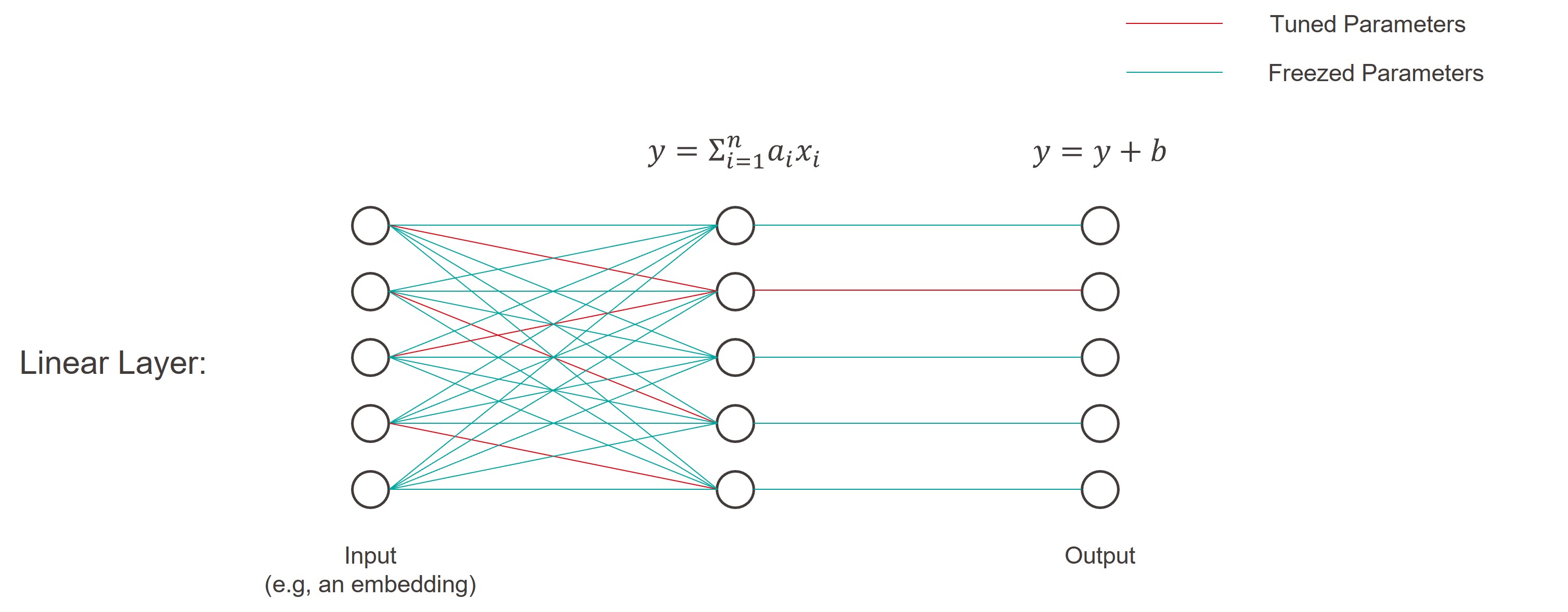 |
|---|
| Illustration of a neural network with random parameter freezing |
Inspired by the paper BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models, we tried to finetune a pretrained BERT model, while freezing different sets of parameters. We compared the performance of the model with the parameters frozen at different levels, and with the parameters not frozen at all.
During our investigation, we verified that freezing up to 99.9% of the parameters of the model can indeed lead to performance similar, if not better, than the performance of the model with all parameters unfrozen. More surprisingly, we found that selecting randomly the parameters to freeze could still compete with the other methods.
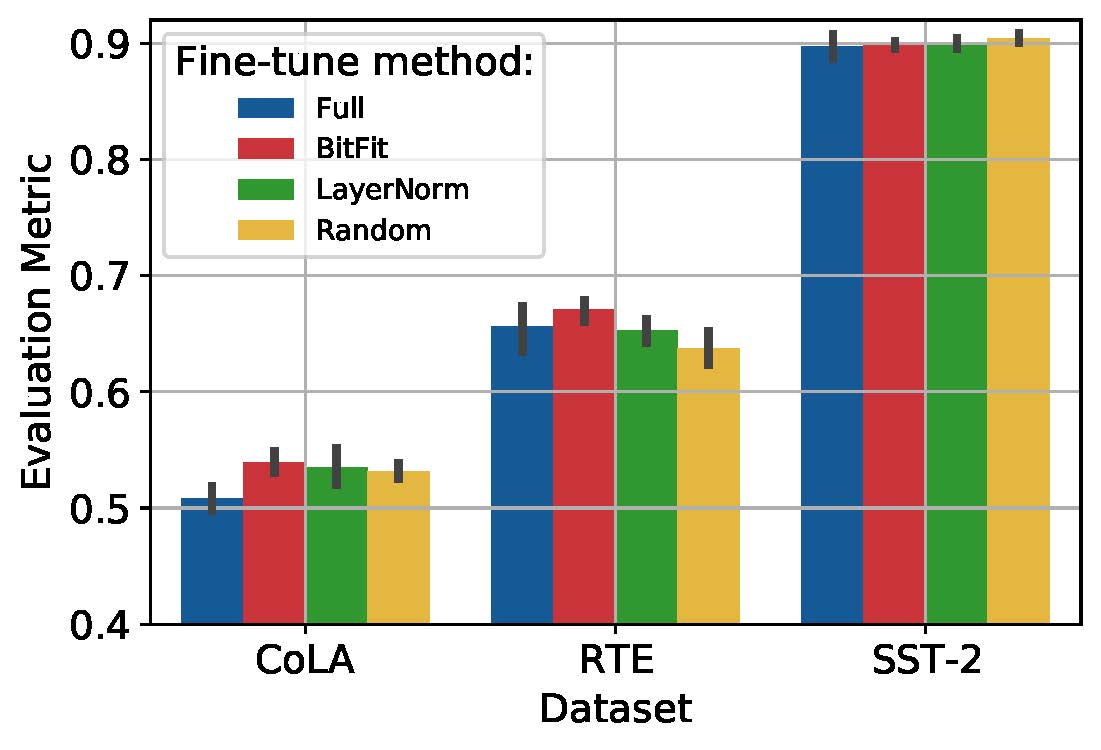 |
|---|
| Evaluation Metrics obtained for the different Methods |

Axel Dinh Van Chi
Computational Science and Engineering Master Graduate from EPFL